
近期推动AI热潮的AI芯片市场主要由NVIDIA主导。但如今,一家新兴的创业公司Cerebras Systems正在试图通过一种革命性的AI芯片打破这一强势地位,这种芯片有望重新定义我们对AI学习的理解。在本文中,我们将探讨Cerebras的创新技术、它对AI未来可能带来的变革,以及它如何与NVIDIA的既有优势竞争。
- Cerebras的推理速度是NVIDIA的20倍
- 在训练过程中与NVIDIA旗鼓相当
- 如果NVIDIA在软件上有所进展,Cerebras可能会面临挑战
もくじ
1. Cerebras的野心:瞄准AI学习过程中的主导地位

Cerebras在众多AI芯片初创公司中独具野心,专注于抢占AI“训练过程”的市场份额,这一领域目前由NVIDIA主导。
补充:什么是AI训练和推理过程?
AI开发包括两个主要阶段:“训练过程”和“推理过程”。
- 训练过程:此阶段通过庞大的数据集来“教导”AI模型。这就像在读教材,需要大量的计算能力来处理数据。
- 推理过程:此阶段,AI模型使用所学内容基于新数据进行预测或决策,类似于在考试或实际情况下应用知识。此阶段关键在于快速处理速度。
近年来,像Groq这样的创业公司开发了专门用于推理过程的AI芯片,挑战NVIDIA的GPU。
然而,在训练过程中,NVIDIA的GPU占据了绝对的市场份额,几乎形成了垄断。
Cerebras的目标是通过开发专门用于训练过程的超大型AI芯片来打破这种垄断。
2. Cerebras的优势:巨大的“晶圆级引擎”芯片
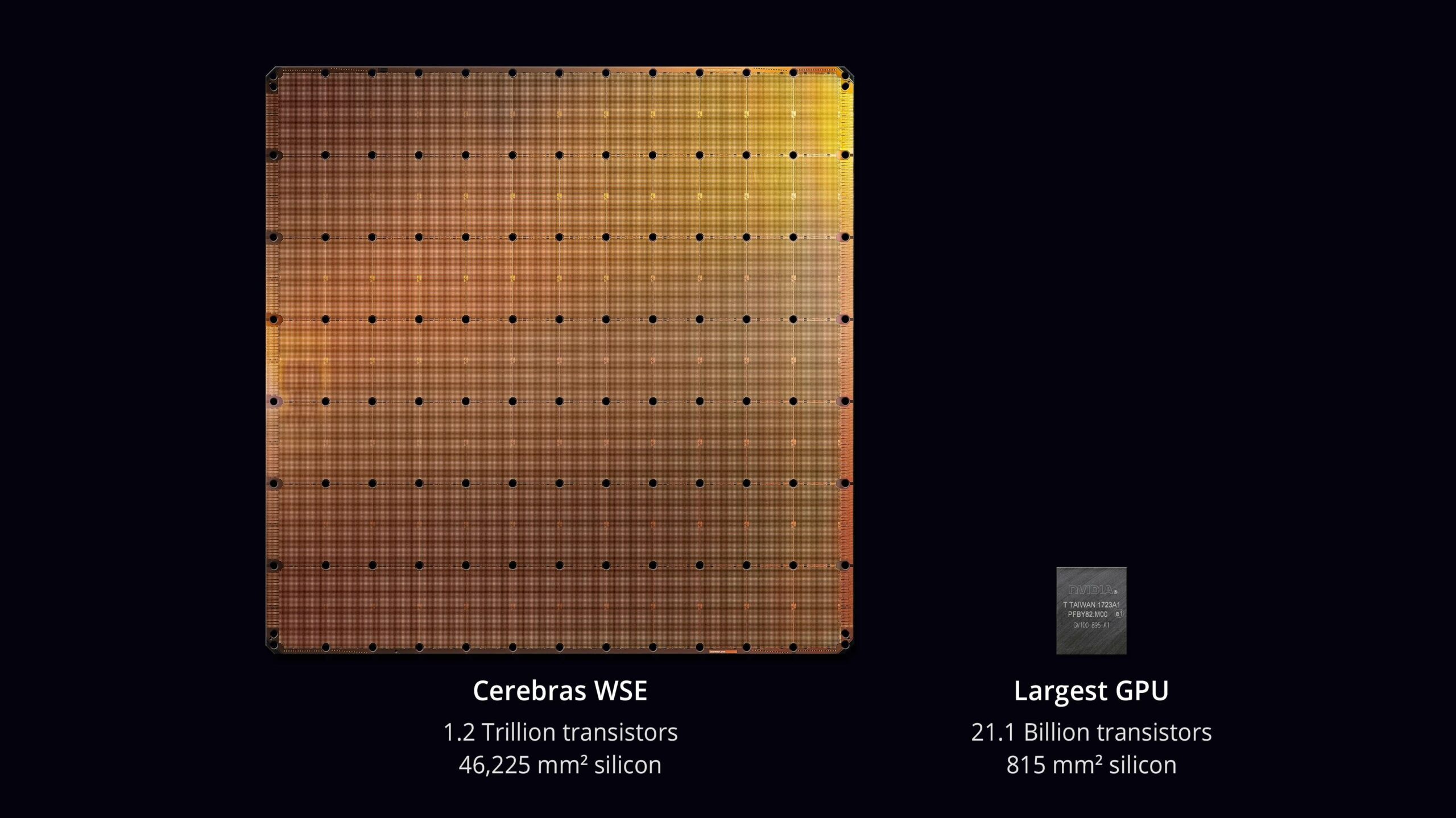
Cerebras的亮点是其巨型芯片“晶圆级引擎(Wafer Scale Engine)”。
传统的芯片从晶圆上切割出来,而Cerebras直接将整个晶圆用作芯片本身。
这被称为晶圆级技术,允许芯片容纳90万个处理器核心,提供传统芯片无法企及的计算能力。
3. 优越的处理速度和编程简便性:与NVIDIA GPU的比较
Cerebras的芯片在AI训练中的处理速度无可比拟,远远超过NVIDIA最新的H100 GPU。
这是通过减少芯片间的通信来实现的,从而消除了传统芯片设计中的瓶颈。
相比需要芯片间通信的NVIDIA GPU,Cerebras的芯片提供了高达3000倍的通信速度提升。
在推理过程中,Cerebras也表现出色,速度高达NVIDIA GPU的20倍,同时降低了功耗和整体运营成本。
此外,Cerebras创建了一种系统,使得其大量芯片集群可以像一个单元一样进行编程,从而简化了具有大规模参数的模型编程,比使用传统GPU提高了24倍的编程效率。
例如,开发一个像GPT-4这样拥有1.7万亿参数的大型语言模型,需要超过240名开发人员,包括35名分布式训练和超级计算的专家。
使用Cerebras芯片可能显著减少这些专家的需求,极大地优化开发资源。
4. 晶圆级芯片的挑战:良率和软件
尽管晶圆级芯片的创新令人瞩目,但较大的芯片通常会有较低的良率(即功能正常的芯片比例)。
然而,Cerebras设计的芯片可以容忍其90万个处理器核心中高达5%的核心失效,使得晶圆级芯片成为可行的方案。
然而,当AI模型过大无法容纳在单个芯片上时,必须将其分割到多个芯片上,需软件来管理这一分割过程。
如果NVIDIA开发出类似的软件以实现平滑的芯片间通信,Cerebras的优势可能会受到威胁。
5. NVIDIA的优势:CUDA带来的GPU编程便捷性

NVIDIA的优势在于其在GPU技术方面的长期经验以及CUDA带来的编程便利性。
CUDA(统一计算设备架构)是NVIDIA开发的平台,旨在简化在GPU上进行的并行编程。
使用CUDA,开发人员可以用熟悉的编程语言(如C++)编写程序,充分利用GPU的性能。
CUDA被广泛采用,拥有大量的软件支持,使得NVIDIA的GPU在AI之外的众多领域(包括游戏和科学计算)中也非常通用。
6. Cerebras在大型语言模型(LLM)中的潜力

Cerebras的芯片在开发大型语言模型(LLM)方面具有巨大潜力,这些模型正受到广泛关注。
LLM的训练需要庞大的数据集,而Cerebras的芯片凭借其强大的处理能力和内存容量,特别适合这种开发。传统上,LLM的训练需要大量时间,但Cerebras有望大幅缩短这一时间。
补充:什么是大型语言模型(LLM)?
LLM(大型语言模型)是用于自然语言处理的AI模型,训练于大量文本数据。
这些模型能够生成类似人类的文本、回答问题以及进行翻译。最近的LLM,如ChatGPT、Gemini和Claude,在AI驱动的自然语言处理方面取得了重大进展。
LLM的关键特征在于其庞大的参数数量和用于训练的大规模数据集。例如,o1-preview拥有2000亿个参数,需要像Cerebras的晶圆级引擎这样强大的AI芯片来训练。
7. 谁能从中受益?Cerebras和NVIDIA的目标用户
谁应该选择Cerebras?
- 前沿AI研究人员:对于从事大型AI模型研究的人员,尤其是在自然语言处理和数据密集型领域,Cerebras是理想选择。
- 开发大型AI模型的企业:企业如果计划开发大型AI模型,例如高精度的聊天机器人或自动驾驶系统,将能从Cerebras的强大处理能力中获益。
- 寻求编程简便性的AI开发者:与多GPU设置的复杂编程相比,Cerebras简化了开发工作,让开发者可以更多关注模型设计和算法。
谁应该选择NVIDIA?
- 跨多个领域的开发者:NVIDIA的GPU不仅用于AI,还广泛应用于游戏、模拟和科学计算。CUDA使得开发多种应用更加容易。
- 注重成本的开发者:预计NVIDIA的GPU更具成本效益,适合预算有限或规模较小的项目。
- 使用丰富工具的开发者:NVIDIA提供了广泛的库和工具(如CUDA),简化了AI开发,并提供了优秀的支持和资源。
8. 结论:AI学习的未来——Cerebras还是NVIDIA?
Cerebras的晶圆级引擎在AI学习过程中提供了突破性的飞跃,具有无与伦比的速度和简化的编程能力。然而,该公司仍面临来自NVIDIA的潜在挑战,尤其是在NVIDIA增强其软件能力的情况下。
随着AI主导地位的竞争日益激烈,未来Cerebras和NVIDIA如何发展将会非常有趣。Cerebras的创新能否带来一个即使是小型开发者也能参与AI学习的未来?时间会给出答案,但可以肯定的是,AI硬件领域即将迎来一次重大转变。
来源:Cerebras AI Day – Opening Keynote – Andrew Feldman – YouTube

コメントする