
O mercado de chips de IA, que impulsionou o recente boom da IA, é amplamente dominado pela NVIDIA. Mas agora, a Cerebras Systems, uma venture emergente, está pronta para desafiar esse domínio com um chip de IA revolucionário que pode redefinir a maneira como abordamos o aprendizado de IA. Neste artigo, exploraremos a tecnologia inovadora da Cerebras, seu potencial para mudar o futuro da IA e como ela se compara ao domínio estabelecido da NVIDIA.
- Cerebras é 20 vezes mais rápida que a NVIDIA em inferência
- Ela rivaliza com a NVIDIA no processo de treinamento
- A Cerebras pode enfrentar desafios se a NVIDIA avançar com seu software
もくじ
- 1. A Ambição da Cerebras: Mirando no Domínio dos Processos de Aprendizado de IA
- 2. A Força da Cerebras: O Gigante Chip “Wafer Scale Engine
- 3. Velocidade de Processamento Excepcional e Simplicidade de Programação: Comparação com as GPUs da NVIDIA
- 4. Desafios dos Chips em Escala de Wafer: Rendimento e Software
- 5. A Força da NVIDIA: A Facilidade de Programação de GPUs com CUDA
- 6. O Potencial da Cerebras em Modelos de Linguagem de Grande Escala (LLMs)
- Suplemento: O Que São os Modelos de Linguagem de Grande Escala (LLMs)?
- 7. Quem se Beneficia? O Público-Alvo da Cerebras e da NVIDIA
- 8. Conclusão: O Futuro do Aprendizado de IA—Cerebras ou NVIDIA?
1. A Ambição da Cerebras: Mirando no Domínio dos Processos de Aprendizado de IA

A Cerebras é uma startup singularmente ambiciosa entre as ventures de chips de IA, focando especificamente em capturar a fatia de mercado do “processo de treinamento” de IA, que atualmente é dominado pela NVIDIA.
Suplemento: O Que São os Processos de Treinamento e Inferência de IA?
O desenvolvimento de IA envolve duas grandes etapas: o “processo de treinamento” e o “processo de inferência”.
- Processo de Treinamento: Esta fase envolve ensinar o modelo de IA com grandes conjuntos de dados. É como estudar livros didáticos, exigindo um poder computacional substancial para processar os dados.
- Processo de Inferência: Aqui, o modelo de IA usa o que aprendeu para prever ou tomar decisões com base em novos dados, semelhante a aplicar o conhecimento em exames ou situações do mundo real. A velocidade de processamento rápido é fundamental nesta fase.
Recentemente, ventures como a Groq desenvolveram chips de IA especificamente para o processo de inferência, competindo com as GPUs da NVIDIA.
No entanto, quando se trata do processo de treinamento, as GPUs da NVIDIA possuem uma participação esmagadora, criando quase um monopólio.
A Cerebras pretende quebrar esse monopólio ao desenvolver um gigantesco chip de IA projetado para o processo de treinamento.
2. A Força da Cerebras: O Gigante Chip “Wafer Scale Engine
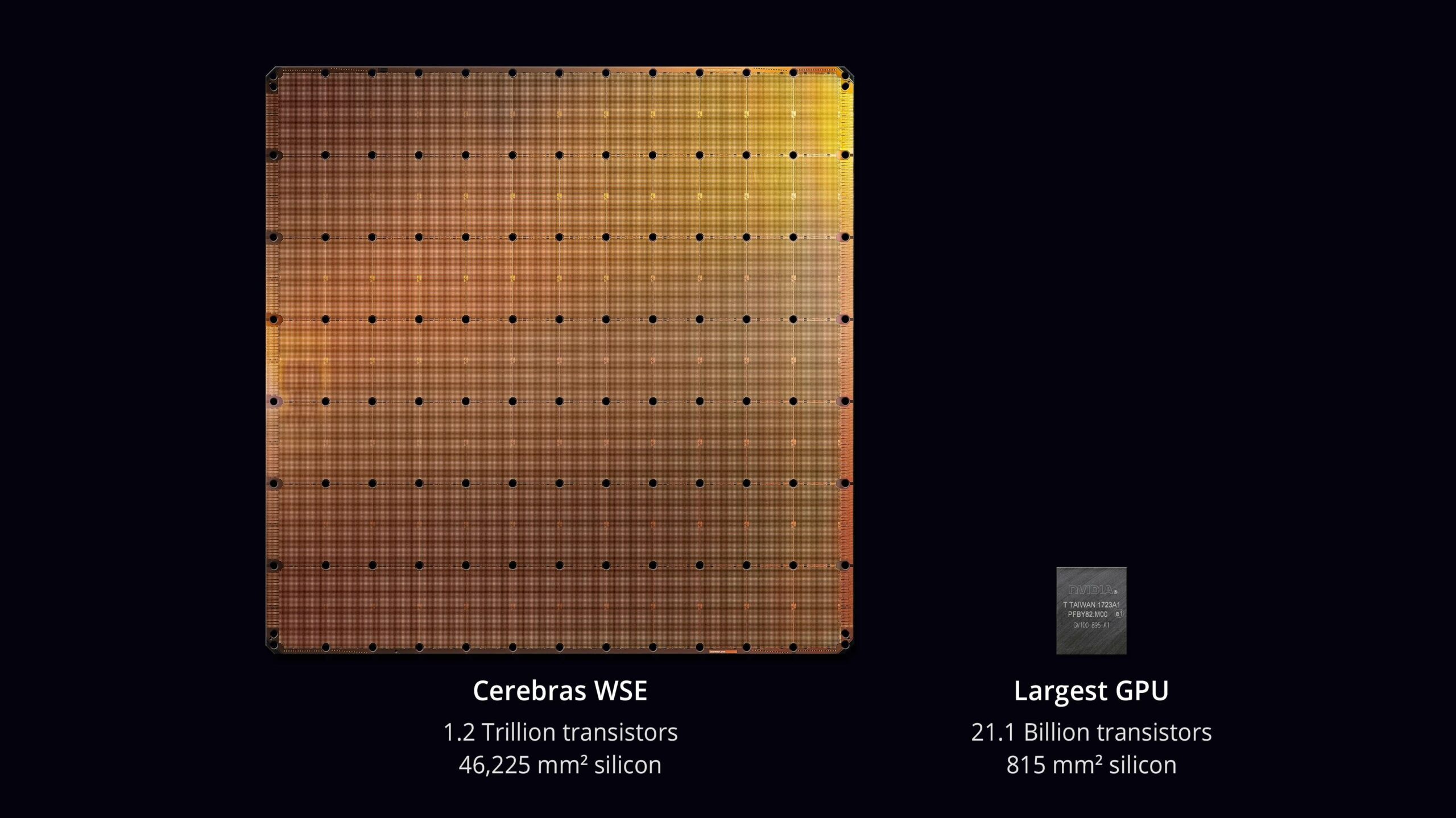
A característica mais marcante da Cerebras é seu chip gigantesco, o “Wafer Scale Engine”.
Enquanto os chips tradicionais são cortados a partir de wafers, a Cerebras usa a wafer inteira como o próprio chip.
Isso é conhecido como escala de wafer, permitindo a inclusão de 900.000 núcleos de processador, oferecendo um poder computacional que antes era impossível com chips convencionais.
3. Velocidade de Processamento Excepcional e Simplicidade de Programação: Comparação com as GPUs da NVIDIA
O chip da Cerebras oferece uma velocidade de processamento inigualável no treinamento de IA, superando em muito a mais recente GPU da NVIDIA, a H100.
Isso é conseguido ao reduzir a comunicação entre chips, eliminando os gargalos vistos em designs tradicionais de chips.
Comparado às GPUs da NVIDIA, que exigem comunicação entre chips, o chip da Cerebras oferece velocidades de comunicação 3.000 vezes mais rápidas.
Na inferência, a Cerebras também supera, sendo até 20 vezes mais rápida que as GPUs da NVIDIA, enquanto reduz o consumo de energia e os custos operacionais gerais.
Além disso, a Cerebras criou um sistema onde grandes clusters de seus chips podem ser programados como se fossem uma única unidade, simplificando a programação de modelos com parâmetros gigantescos em um fator de 24 vezes em comparação com o uso de GPUs tradicionais.
Por exemplo, desenvolver um grande modelo de linguagem como o GPT-4, que contém 1,7 trilhões de parâmetros, exigiu mais de 240 desenvolvedores, incluindo 35 especialistas em treinamento distribuído e supercomputação.
Usar chips da Cerebras pode potencialmente reduzir a necessidade desses especialistas, otimizando significativamente os recursos de desenvolvimento.
4. Desafios dos Chips em Escala de Wafer: Rendimento e Software
Embora a inovação dos chips em escala de wafer seja notável, chips maiores tendem a ter menor rendimento (a proporção de chips funcionais).
No entanto, a Cerebras projetou seu chip para tolerar até 5% de seus 900.000 núcleos de processador com defeito, tornando o chip de escala de wafer viável.
Ainda assim, quando os modelos de IA se tornam grandes demais para caber em um único chip, eles precisam ser divididos em vários chips, exigindo software para gerenciar essa divisão.
Se a NVIDIA desenvolver um software semelhante para uma comunicação suave entre chips, a vantagem da Cerebras pode ser ameaçada.
5. A Força da NVIDIA: A Facilidade de Programação de GPUs com CUDA

A força da NVIDIA reside em sua longa experiência com a tecnologia de GPUs e na facilidade de programação proporcionada pelo CUDA.
CUDA (Compute Unified Device Architecture) é uma plataforma desenvolvida pela NVIDIA para simplificar a programação paralela em GPUs.
Com o CUDA, os desenvolvedores podem escrever programas em linguagens familiares como C++, aproveitando totalmente o desempenho das GPUs.
O CUDA é amplamente adotado, com amplo suporte de software, tornando as GPUs da NVIDIA versáteis em uma variedade de campos além da IA, incluindo jogos e computação científica.
6. O Potencial da Cerebras em Modelos de Linguagem de Grande Escala (LLMs)

O chip da Cerebras é particularmente promissor para o desenvolvimento de grandes modelos de linguagem (LLMs), que estão ganhando atenção significativa.
Os LLMs requerem enormes conjuntos de dados para treinamento, e o chip da Cerebras, com sua imensa capacidade de processamento e memória, é ideal para esse desenvolvimento. Tradicionalmente, o treinamento de LLMs levava muito tempo, mas a Cerebras pode reduzir drasticamente esse tempo.
Suplemento: O Que São os Modelos de Linguagem de Grande Escala (LLMs)?
LLMs (Modelos de Linguagem de Grande Escala) são modelos de IA treinados em grandes quantidades de dados de texto para processamento de linguagem natural.
Esses modelos podem gerar texto semelhante ao humano, responder perguntas e realizar traduções. Recentes LLMs, como o ChatGPT o1-preview, Gemini e Claude, trouxeram grandes avanços no processamento de linguagem natural conduzido por IA.
A característica chave dos LLMs é seu vasto número de parâmetros e os enormes conjuntos de dados usados para treinamento. Por exemplo, o o1-preview possui 200 bilhões de parâmetros, exigindo um poderoso chip de IA para treinamento, como o Wafer Scale Engine da Cerebras.
7. Quem se Beneficia? O Público-Alvo da Cerebras e da NVIDIA
Quem Deve Escolher a Cerebras?
- Pesquisadores de IA de ponta: A Cerebras é perfeita para pesquisadores que trabalham com grandes modelos de IA, especialmente em campos como o processamento de linguagem natural e setores que lidam com grandes volumes de dados.
- Empresas desenvolvendo grandes modelos de IA: Empresas que visam usar grandes modelos de IA, como chatbots de alta precisão ou sistemas de direção autônoma, se beneficiarão dopoder de processamento da Cerebras.
- Desenvolvedores de IA que buscam simplicidade de programação: A Cerebras simplifica a programação complexa necessária para configurações com múltiplas GPUs, permitindo que os desenvolvedores se concentrem no design do modelo e nos algoritmos.
Quem Deve Escolher a NVIDIA?
- Desenvolvedores em vários campos: As GPUs da NVIDIA são usadas não apenas em IA, mas também em jogos, simulações e computação científica. O CUDA facilita o desenvolvimento de uma ampla gama de aplicações.
- Desenvolvedores com orçamento limitado: Espera-se que as GPUs da NVIDIA sejam mais acessíveis, tornando-as adequadas para desenvolvedores com orçamento apertado ou para projetos menores.
- Desenvolvedores que utilizam um conjunto de ferramentas rico: A NVIDIA oferece um ecossistema extenso de bibliotecas e ferramentas, como o CUDA, que agilizam o desenvolvimento de IA e oferecem excelente suporte e recursos.
8. Conclusão: O Futuro do Aprendizado de IA—Cerebras ou NVIDIA?
O Wafer Scale Engine da Cerebras oferece um salto transformador nos processos de aprendizado de IA, com sua velocidade incomparável e capacidades de programação simplificadas. No entanto, a empresa enfrenta potenciais desafios da NVIDIA, especialmente se a NVIDIA fortalecer suas capacidades de software.
À medida que a corrida pelo domínio da IA esquenta, será fascinante ver como a Cerebras e a NVIDIA continuarão a evoluir. A inovação da Cerebras poderia levar a um futuro em que até mesmo pequenos desenvolvedores possam participar do aprendizado de IA? Só o tempo dirá, mas é certo que o cenário do hardware de IA está à beira de uma grande mudança.
Fonte:Cerebras AI Day – Opening Keynote – Andrew Feldman – YouTube
Fonte:Como a Cerebras está rompendo o gargalo das GPUs na inferência de IA

コメントする