
최근 AI 붐을 지탱하는 AI 칩 시장에서는 NVIDIA가 압도적인 점유율을 자랑하고 있습니다. 하지만 그 아성에 도전장을 내민 기업이 있습니다. 바로 Cerebras Systems라는 벤처 기업입니다. Cerebras는 기존 상식을 뒤엎는 거대한 AI 칩을 개발하여 NVIDIA의 아성을 무너뜨리려 하고 있습니다.
이 글에서는 Cerebras의 혁신적인 기술과 그 가능성, 그리고 NVIDIA와의 차이점에 대해 알기 쉽게 설명합니다.
- Cerebras는 추론에서 NVIDIA보다 20배 빠름
- 학습 과정에서도 NVIDIA에 필적
- NVIDIA가 소프트웨어를 발전시키면 Cerebras의 미래는 불투명
もくじ
- 1. Cerebras의 야망: AI 학습 과정의 패권을 노린다
- 2. Cerebras의 강점: 거대 칩 “Wafer Scale Engine”
- 3. 놀라운 처리 속도와 프로그래밍의 간결함: NVIDIA GPU와의 비교
- 4. 웨이퍼 크기 칩의 과제: 수율과 소프트웨어
- 5. NVIDIA의 강점: CUDA를 통해 GPU 프로그래밍을 쉽게 할 수 있다
- 6. 대규모 언어 모델(LLM)에서 Cerebras의 활약이 기대된다
- 7. 어떤 쪽이 적합할까?: Cerebras와 NVIDIA의 타겟층
- 8. 결론: Cerebras는 거인 NVIDIA를 쓰러뜨릴 수 있을까?
1. Cerebras의 야망: AI 학습 과정의 패권을 노린다

Cerebras는 여러 AI 칩 벤처 기업 중 유일하게 NVIDIA가 독점하고 있는 AI “학습 과정”에서의 점유율 확보를 진심으로 목표하는 야심 찬 벤처입니다.
보충: AI의 학습 과정과 추론 과정이란?
AI 개발에는 크게 나누어 “학습 과정”과 “추론 과정”의 두 단계가 있습니다.
- 학습 과정: 방대한 데이터를 사용하여 AI 모델을 학습시키는 단계입니다. 사람으로 비유하면 교과서나 참고서를 읽고 공부하는 단계에 해당합니다. 이 단계에서는 방대한 데이터를 처리할 수 있는 높은 연산 능력이 요구됩니다.
- 추론 과정: 학습된 AI 모델을 사용하여 새로운 데이터에 대한 예측이나 판단을 수행하는 단계입니다. 사람으로 비유하면 시험 문제를 풀거나 실생활에서 지식을 활용하는 단계에 해당합니다. 이 단계에서는 신속한 판단을 수행하기 위한 처리 속도가 중요합니다.
최근 Groq 등의 AI 칩 벤처 기업들이 추론 과정에 특화된 AI 칩을 개발하여 NVIDIA의 GPU에 대항하고 있습니다.
하지만 학습 과정에서는 여전히 NVIDIA의 GPU가 압도적인 점유율을 자랑하며 사실상 독점 상태를 유지하고 있습니다.
Cerebras는 이 학습 과정에 특화된 거대한 AI 칩을 개발함으로써 NVIDIA의 아성을 무너뜨리려 하고 있습니다.
2. Cerebras의 강점: 거대 칩 “Wafer Scale Engine”
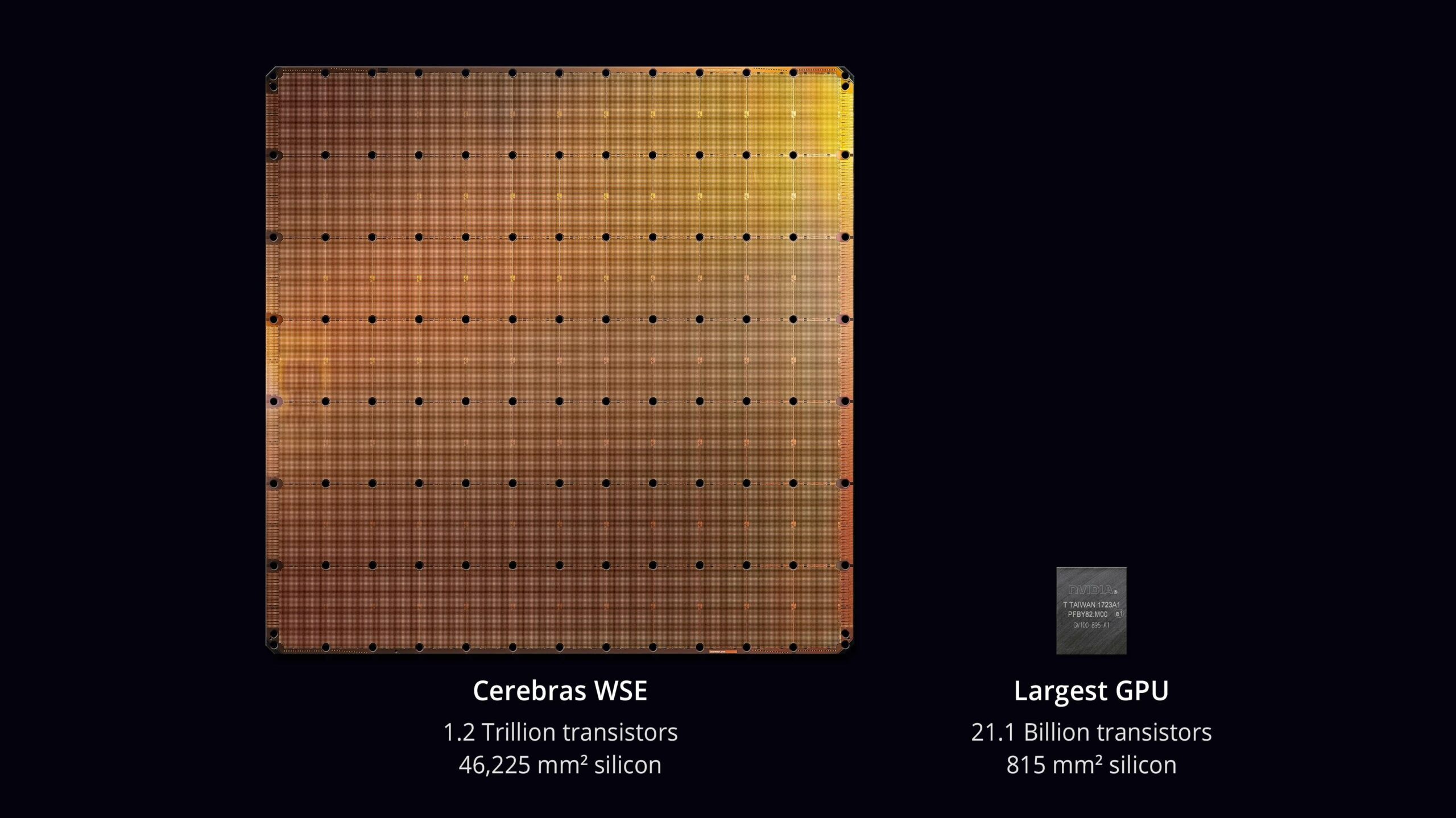
Cerebras의 가장 큰 특징은 “Wafer Scale Engine”이라고 불리는 거대한 칩입니다.
일반적인 칩은 웨이퍼에서 잘라낸 작은 칩이지만, Cerebras는 웨이퍼 자체를 칩으로 활용하고 있습니다.
이를 웨이퍼 스케일이라고 부르며, 엄청난 수의 프로세서 코어(90만 개)를 탑재하는 것을 가능하게 하여 기존 칩에서는 불가능했던 처리 능력을 실현하고 있습니다.
3. 놀라운 처리 속도와 프로그래밍의 간결함: NVIDIA GPU와의 비교
Cerebras의 칩은 AI 학습 과정에서 NVIDIA의 최신 GPU인 H100과 비교하여 압도적인 처리 속도를 자랑합니다.
이는 거대한 칩으로 인해 칩 간 통신을 줄이고 처리 병목 현상을 해소했기 때문입니다.
칩 간 통신이 필요한 NVIDIA의 GPU와 비교하여 Cerebras의 칩은 3000배 이상의 통신 속도를 실현했다고 합니다.
또한 AI 추론 과정에서도 NVIDIA의 GPU보다 최대 20배 빠르게 처리할 수 있는 놀라운 성능을 실현하고 있으며, 전력 소비와 처리 시간 단축을 통해 운영 비용 전체를 절감할 수 있는 가능성이 있습니다.
더 나아가 Cerebras는 거대한 칩을 클러스터화하여 연결해도 마치 하나의 칩처럼 프로그래밍할 수 있는 환경을 구축했습니다.
그 결과, 거대한 파라미터 수를 가진 LLM의 프로그래밍이 기존 GPU를 사용했을 때와 비교하여 (코드량 기준) 24배 간단해졌다고 합니다.
예를 들어 1.7조 파라미터를 가진 거대 언어 모델 “GPT-4” 개발에는 240명 이상의 개발자가 참여했고, 그중 35명은 분산 학습과 슈퍼컴퓨팅 전문가였다고 합니다.
Cerebras의 칩을 사용하면 GPT-4와 같은 거대한 모델 개발에서도 분산 학습 전문가 35명을 줄일 수 있는 가능성이 있으며, 개발 리소스 효율화를 꾀할 수 있습니다.
4. 웨이퍼 크기 칩의 과제: 수율과 소프트웨어
웨이퍼 스케일의 거대 칩을 만드는 혁신적인 아이디어는 훌륭하지만, 칩의 크기가 커지면 수율(정상적으로 작동하는 칩의 비율)이 극단적으로 낮아지는 것이 과제입니다.
하지만 Cerebras는 90만 개의 프로세서 코어 중 5%가 불량품이어도 문제없도록 설계하여 웨이퍼 크기 칩의 운영이 가능하도록 했다고 합니다.
그럼에도 불구하고 하나의 칩으로 처리할 수 없을 정도로 거대한 모델이 등장할 경우, 여러 칩으로 분할하여 처리하고 그 부분은 소프트웨어로 보완해야 합니다.
그리고 만약 NVIDIA가 유사한 칩 간 연동 소프트웨어를 제공하게 된다면 Cerebras의 우위는 사라질 가능성도 우려됩니다.
5. NVIDIA의 강점: CUDA를 통해 GPU 프로그래밍을 쉽게 할 수 있다

NVIDIA의 강점은 GPU 기술에 대한 오랜 경험과 CUDA를 통해 구축된 GPU 프로그래밍의 쉬운 사용성에 있습니다.
CUDA(Compute Unified Device Architecture)는 NVIDIA가 개발한 GPU를 사용한 병렬 처리 프로그래밍을 쉽게 해주는 플랫폼입니다.
CUDA를 사용하면 C++ 언어 등 익숙한 언어로 GPU의 성능을 최대한 활용하는 프로그램을 작성할 수 있습니다.
CUDA는 널리 보급되어 있으며 많은 소프트웨어가 CUDA를 지원하기 때문에 NVIDIA의 GPU는 AI 학습 및 추론뿐만 아니라 게임, 과학 계산 등 광범위한 용도로 활용되고 있습니다.
6. 대규모 언어 모델(LLM)에서 Cerebras의 활약이 기대된다

Cerebras의 칩은 특히 최근 주목받고 있는 대규모 언어 모델(LLM) 개발에서 큰 힘을 발휘할 것으로 기대됩니다.
LLM은 방대한 데이터를 사용하여 학습하기 때문에 Cerebras 칩이 가진 압도적인 처리 능력과 메모리 용량은 LLM 개발에 최적입니다. 기존에는 LLM 학습에 엄청난 시간이 소요되었지만, Cerebras 칩을 통해 학습 시간을 대폭 단축할 수 있는 가능성이 있습니다.
보충: 대규모 언어 모델(LLM)이란?
대규모 언어 모델(LLM: Large Language Model)이란 방대한 텍스트 데이터를 사용하여 학습된 자연어 처리를 수행하는 AI 모델입니다.
LLM은 사람처럼 자연스러운 문장을 생성하거나 질문에 답변하거나 번역할 수 있습니다. 최근 ChatGPT o1-preview, Gemini, Claude와 같은 고성능 LLM이 등장하면서 AI 기반 자연어 처리는 큰 진전을 이루었습니다.
LLM의 특징은 거대한 파라미터 수와 학습에 사용하는 데이터량의 많음에 있습니다. 예를 들어 o1-preview는 2000억 개의 파라미터를 가지고 있어 매우 높은 연산 능력과 메모리 용량을 가진 AI 칩이 필요합니다.
Cerebras의 Wafer Scale Engine은 바로 LLM 학습에 최적의 AI 칩이라고 할 수 있습니다.
7. 어떤 쪽이 적합할까?: Cerebras와 NVIDIA의 타겟층
Cerebras에 적합한 사용자
- 최첨단 AI 연구자: 거대한 AI 모델을 다루는 최첨단 연구를 수행하고 처리 속도를 극한까지 추구하는 연구자에게 Cerebras는 강력한 도구입니다. 특히 자연어 처리 등 대규모 데이터셋을 다루는 분야에서는 이 처리 능력이 큰 장점이 될 것입니다.
- 대규모 AI 모델을 다루는 기업: 대규모 AI 모델을 비즈니스에 활용하고자 하는 기업에게도 Cerebras는 매력적입니다. 예를 들어 거대한 언어 모델을 활용한 고정밀 챗봇 개발이나 방대한 이미지 데이터를 처리하는 자율 주행 시스템 개발 등 Cerebras의 처리 능력은 경쟁력을 높이는 데 중요한 역할을 할 것입니다.
- 복잡한 프로그래밍에서 벗어나고 싶은 AI 개발자: GPU를 사용한 AI 개발에서는 여러 GPU를 연동하기 위한 복잡한 프로그래밍이 필요했습니다. Cerebras는 거대한 단일 칩으로 처리하기 때문에 프로그래밍이 크게 간소화됩니다. 이를 통해 AI 개발자는 모델 설계 및 학습 알고리즘 개발과 같은 본질적인 부분에 집중할 수 있습니다.
NVIDIA에 적합한 사용자
- 폭넓은 분야의 개발자: NVIDIA의 GPU는 AI뿐만 아니라 게임, 시뮬레이션, 과학 계산 등 폭넓은 분야에서 활용됩니다. CUDA와 그 생태계를 활용하여 다양한 애플리케이션을 효율적으로 개발할 수 있습니다.
- 가성비를 중시하는 개발자: NVIDIA의 GPU는 Cerebras 칩과 비교하여 저렴할 것으로 예상되며, 폭넓은 가격대의 제품이 라인업되어 있습니다. 따라서 예산을 절감하고 싶은 개발자나 소규모 프로젝트에 적합합니다.
- 풍부한 라이브러리와 도구를 활용하고 싶은 개발자: NVIDIA는 CUDA를 비롯한 풍부한 라이브러리와 도구를 제공합니다. 이를 활용하여 AI 개발을 효율적으로 진행할 수 있습니다. 또한 많은 개발자가 CUDA에 정통하기 때문에 정보 공유 및 기술 지원을 받기 쉽다는 장점도 있습니다.
8. 결론: Cerebras는 거인 NVIDIA를 쓰러뜨릴 수 있을까?
Cerebras는 웨이퍼 스케일의 거대 칩을 통해 AI 학습의 처리 속도와 프로그래밍의 용이성을 비약적으로 향상시킬 가능성을 가지고 있습니다.
하지만 AI 모델의 거대화는 앞으로도 계속될 가능성이 높고, Cerebras의 칩으로도 처리하기 힘든 상황이 올 수도 있습니다.
또한 NVIDIA가 칩 간 연동을 원활하게 수행하는 소프트웨어를 개발한다면 Cerebras의 우위가 사라질 가능성도 있습니다.
앞으로 Cerebras처럼 학습 과정을 간편하게 만드는 기업이 늘어나 서로 경쟁함으로써 AI 학습 및 개발을 개인도 할 수 있는 시대가 올지 모릅니다.
그런 미래가 실현되어 개인이 AI 학습에서도 활약할 수 있게 되기를 기대합니다!
참고: Cerebras AI Day – Opening Keynote – Andrew Feldman – YouTube

コメントする