
El mercado de chips de IA, que ha estado impulsando el reciente auge de la IA, está dominado en gran medida por NVIDIA. Pero ahora, Cerebras Systems, una empresa emergente en ascenso, aspira a interrumpir este bastión con un chip de IA revolucionario que podría redefinir la forma en que abordamos el aprendizaje de la IA. En este artículo, exploraremos la tecnología innovadora de Cerebras, su potencial para cambiar el futuro de la IA y cómo se compara con el dominio establecido de NVIDIA.
- Cerebras es 20 veces más rápido que NVIDIA en inferencia
- Rivaliza con NVIDIA en el proceso de entrenamiento
- Cerebras puede enfrentar desafíos si NVIDIA avanza su software
もくじ
- 1. La ambición de Cerebras: apuntar al dominio en los procesos de aprendizaje de la IA
- 2. La fuerza de Cerebras: el chip gigante «»Wafer Scale Engine»»
- 3. Velocidad de procesamiento excepcional y simplicidad de programación: comparación con las GPU de NVIDIA
- 4. Desafíos de los chips a escala de oblea: rendimiento y software
- 5. La fuerza de NVIDIA: la facilidad de programación de GPU con CUDA
- 6. El potencial de Cerebras en modelos de lenguaje grandes (LLM)
- 7. ¿Quién se beneficia? El público objetivo de Cerebras y NVIDIA
- 8. Conclusión: el futuro del aprendizaje de la IA: ¿Cerebras o NVIDIA?
1. La ambición de Cerebras: apuntar al dominio en los procesos de aprendizaje de la IA

Cerebras es una startup excepcionalmente ambiciosa entre las empresas de chips de IA, que se centra específicamente en capturar la cuota de mercado del «»proceso de entrenamiento»» de la IA, que NVIDIA domina actualmente.
Suplemento: ¿Qué son los procesos de entrenamiento e inferencia de la IA?
El desarrollo de la IA implica dos etapas principales: el «»proceso de entrenamiento»» y el «»proceso de inferencia»».
- Proceso de entrenamiento: Esta etapa implica enseñar al modelo de IA con conjuntos de datos masivos. Es como estudiar libros de texto, lo que requiere una potencia computacional sustancial para procesar los datos.
- Proceso de inferencia: Aquí, el modelo de IA utiliza lo que ha aprendido para predecir o tomar decisiones basadas en nuevos datos, similar a la aplicación del conocimiento en exámenes o situaciones del mundo real. La velocidad de procesamiento rápida es clave en esta etapa.
Recientemente, empresas como Groq han desarrollado chips de IA específicamente para el proceso de inferencia, compitiendo con las GPU de NVIDIA.
Sin embargo, cuando se trata del proceso de entrenamiento, las GPU de NVIDIA tienen una participación abrumadora, creando un casi monopolio.
Cerebras tiene como objetivo romper este monopolio desarrollando un chip de IA masivo diseñado para el proceso de entrenamiento.
2. La fuerza de Cerebras: el chip gigante «»Wafer Scale Engine»»
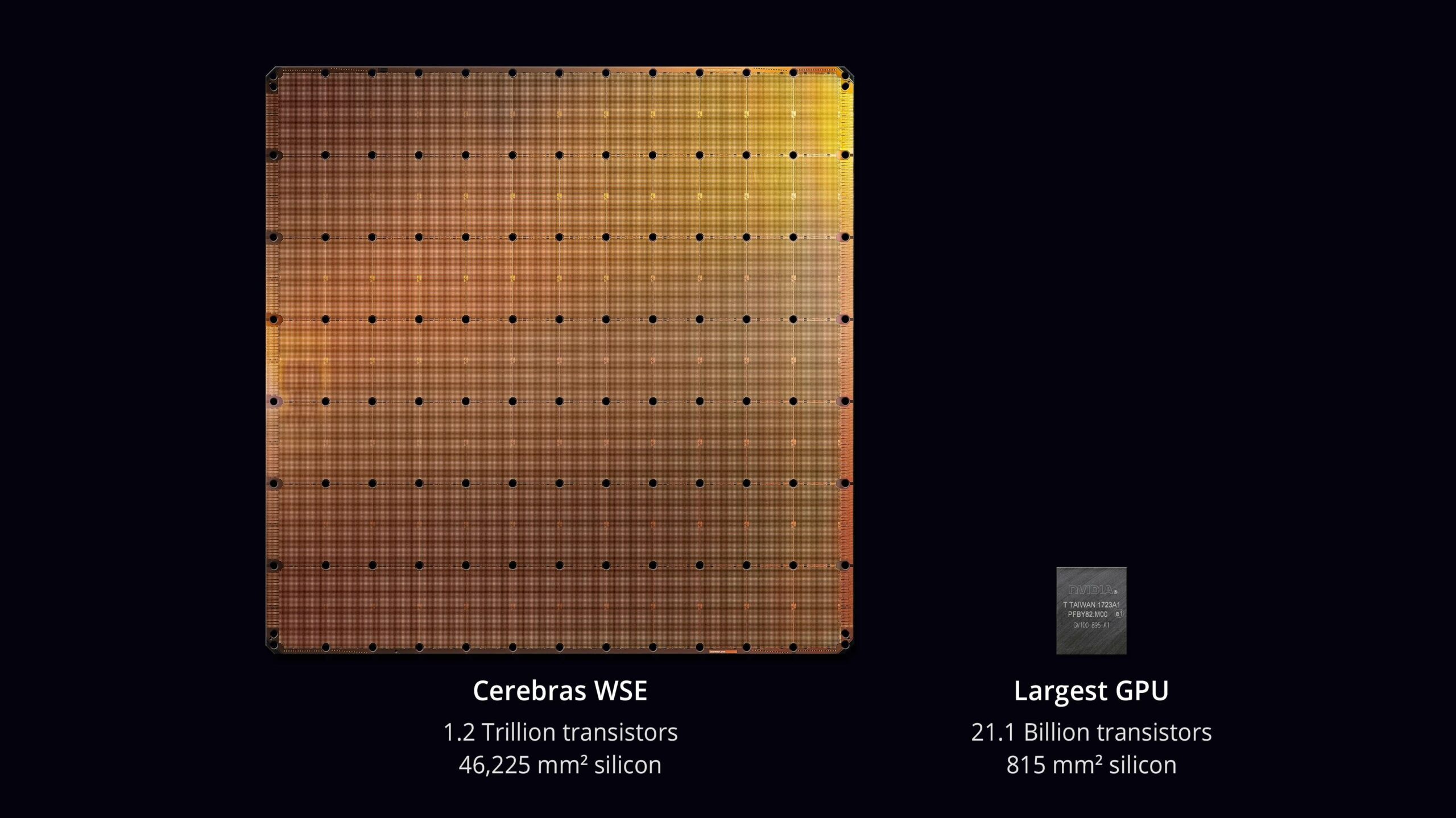
La característica destacada de Cerebras es su chip masivo, el «»Wafer Scale Engine»».
Mientras que los chips tradicionales se cortan de obleas, Cerebras utiliza la oblea completa como el chip en sí.
Esto se conoce como escala de oblea, lo que permite la inclusión de 900.000 núcleos de procesador, brindando una potencia computacional que antes era imposible con los chips convencionales.
3. Velocidad de procesamiento excepcional y simplicidad de programación: comparación con las GPU de NVIDIA
El chip de Cerebras cuenta con una velocidad de procesamiento incomparable en el entrenamiento de IA, superando con creces la última GPU de NVIDIA, la H100.
Esto se logra al reducir la comunicación entre chips, eliminando los cuellos de botella que se ven en los diseños de chips tradicionales.
En comparación con las GPU de NVIDIA, que requieren comunicación entre chips, el chip de Cerebras ofrece velocidades de comunicación 3.000 veces más rápidas.
En la inferencia, Cerebras también supera, siendo hasta 20 veces más rápido que las GPU de NVIDIA, al tiempo que reduce el consumo de energía y los costos operativos generales.
Además, Cerebras ha creado un sistema donde grandes grupos de sus chips se pueden programar como si fueran una sola unidad, simplificando la programación para modelos con parámetros masivos por un factor de 24 veces en comparación con el uso de GPU tradicionales.
Por ejemplo, el desarrollo de un modelo de lenguaje grande como GPT-4, que contiene 1,7 billones de parámetros, requirió más de 240 desarrolladores, incluidos 35 expertos en entrenamiento distribuido y supercomputación.
El uso de chips Cerebras podría reducir potencialmente la necesidad de estos especialistas, optimizando significativamente los recursos de desarrollo.
4. Desafíos de los chips a escala de oblea: rendimiento y software
Si bien la innovación de los chips a escala de oblea es notable, los chips más grandes tienden a tener un rendimiento menor (la proporción de chips que funcionan).
Sin embargo, Cerebras ha diseñado su chip para tolerar hasta un 5% de sus 900.000 núcleos de procesador defectuosos, lo que hace que el chip a escala de oblea sea factible.
Aún así, cuando los modelos de IA se vuelven demasiado grandes para caber en un solo chip, deben dividirse en varios chips, lo que requiere software para administrar esta división.
Si NVIDIA desarrolla un software similar para una comunicación fluida entre chips, la ventaja de Cerebras puede verse amenazada.
5. La fuerza de NVIDIA: la facilidad de programación de GPU con CUDA

La fuerza de NVIDIA radica en su larga experiencia con la tecnología GPU y la facilidad de programación que proporciona CUDA.
CUDA (Compute Unified Device Architecture) es una plataforma desarrollada por NVIDIA para simplificar la programación paralela en GPU.
Con CUDA, los desarrolladores pueden escribir programas en lenguajes familiares como C++, utilizando plenamente el rendimiento de la GPU.
CUDA es ampliamente adoptado, con un amplio soporte de software, lo que hace que las GPU de NVIDIA sean versátiles en una variedad de campos más allá de la IA, incluidos los juegos y la informática científica.
6. El potencial de Cerebras en modelos de lenguaje grandes (LLM)

El chip de Cerebras es particularmente prometedor para desarrollar modelos de lenguaje grandes (LLM), que están ganando una atención significativa.
Los LLM requieren conjuntos de datos masivos para el entrenamiento, y el chip de Cerebras, con su inmensa potencia de procesamiento y capacidad de memoria, es ideal para dicho desarrollo. Tradicionalmente, el entrenamiento de LLM tomaba un tiempo considerable, pero Cerebras puede reducirlo drásticamente.
Suplemento: ¿Qué son los modelos de lenguaje grandes (LLM)?
Los LLM (Modelos de lenguaje grandes) son modelos de IA entrenados en grandes cantidades de datos de texto para el procesamiento del lenguaje natural.
Estos modelos pueden generar texto similar al humano, responder preguntas y realizar traducciones. Los LLM recientes como ChatGPT o1-preview, Gemini y Claude han traído avances importantes en el procesamiento del lenguaje natural impulsado por IA.
La característica clave de los LLM es su gran cantidad de parámetros y los enormes conjuntos de datos utilizados para el entrenamiento. Por ejemplo, o1-preview tiene 200 mil millones de parámetros, lo que requiere un potente chip de IA para el entrenamiento, como el Wafer Scale Engine de Cerebras.
7. ¿Quién se beneficia? El público objetivo de Cerebras y NVIDIA
¿Quién debería elegir Cerebras?
- Investigadores de IA de vanguardia: Cerebras es perfecto para investigadores que trabajan con grandes modelos de IA, especialmente en campos como el procesamiento del lenguaje natural y sectores con muchos datos.
- Empresas que desarrollan grandes modelos de IA: Las empresas que buscan utilizar grandes modelos de IA, como chatbots de alta precisión o sistemas de conducción autónoma, se beneficiarán de la potencia de procesamiento de Cerebras.
- Desarrolladores de IA que buscan simplicidad de programación: Cerebras simplifica la programación compleja requerida para configuraciones de múltiples GPU, lo que permite a los desarrolladores centrarse en el diseño de modelos y algoritmos.
¿Quién debería elegir NVIDIA?
- Desarrolladores en múltiples campos: Las GPU de NVIDIA se utilizan no solo en IA, sino también en juegos, simulaciones e informática científica. CUDA facilita el desarrollo de una amplia gama de aplicaciones.
- Desarrolladores preocupados por los costos: Se espera que las GPU de NVIDIA sean más asequibles, lo que las hace adecuadas para desarrolladores con un presupuesto limitado o para proyectos más pequeños.
- Desarrolladores que utilizan un amplio conjunto de herramientas: NVIDIA ofrece un extenso ecosistema de bibliotecas y herramientas como CUDA, que agilizan el desarrollo de IA y brindan un excelente soporte y recursos.
8. Conclusión: el futuro del aprendizaje de la IA: ¿Cerebras o NVIDIA?
Wafer Scale Engine de Cerebras ofrece un salto transformador en los procesos de aprendizaje de la IA, con su velocidad incomparable y capacidades de programación simplificadas. Sin embargo, la empresa se enfrenta a posibles desafíos de NVIDIA, especialmente si NVIDIA fortalece sus capacidades de software.
A medida que se intensifica la carrera por el dominio de la IA, será fascinante ver cómo Cerebras y NVIDIA continúan evolucionando. ¿Podría la innovación de Cerebras conducir a un futuro en el que incluso los pequeños desarrolladores puedan participar en el aprendizaje de la IA? Solo el tiempo lo dirá, pero es seguro que el panorama del hardware de IA está al borde de un cambio importante.
Fuente:Cerebras AI Day – Opening Keynote – Andrew Feldman – YouTube
Fuente:Cómo Cerebras está rompiendo el cuello de botella de la GPU en la inferencia de IA

コメントする