
近年のAIブームを支えるAIチップ市場では、NVIDIAが圧倒的なシェアを誇っています。しかし、そこに風穴を開けようとしているのが、Cerebras Systemsというベンチャー企業です。Cerebrasは、従来の常識を覆す巨大なAIチップを開発し、NVIDIAの牙城を崩そうとしています。
この記事では、Cerebrasの革新的な技術とその可能性、そしてNVIDIAとの違いについて、わかりやすく解説します。
- Cerebrasは、推論でNVIDIAの20倍高速
- 学習プロセスでもNVIDIAに匹敵
- NVIDIAがソフトを進化させた場合は危うい
もくじ
1. Cerebrasの野望:AI学習プロセスの覇権を狙う

Cerebrasは、複数あるAIチップベンチャーの中で唯一、NVIDIAが独占しているAIの「学習プロセス」におけるシェア獲得を本気で目指している野心的なベンチャーです。
補足:AIの学習プロセスと推論プロセスとは?
AI開発には、大きく分けて「学習プロセス」と「推論プロセス」の2つの段階があります。
- 学習プロセス:大量のデータを使ってAIモデルに学習させる段階です。人間で例えると、教科書や参考書を読んで勉強する段階に当たります。この段階では、大量のデータを処理できる高い計算能力が求められます。
- 推論プロセス:学習済みのAIモデルを使って、新たなデータに対して予測や判断を行う段階です。人間で例えると、試験問題を解いたり、実社会で知識を活用する段階に当たります。この段階では、迅速な判断を行うための処理速度が重要になります。
近年、GroqなどのAIチップベンチャーが、推論プロセスに特化したAIチップを開発し、NVIDIAのGPUに対抗しています。
しかし、学習プロセスにおいては、依然としてNVIDIAのGPUが圧倒的なシェアを誇っており、事実上の独占状態となっています。
Cerebrasは、この学習プロセスに特化した巨大なAIチップを開発することで、NVIDIAの牙城を崩そうとしています。
2. Cerebrasの強み:巨大チップ「Wafer Scale Engine」
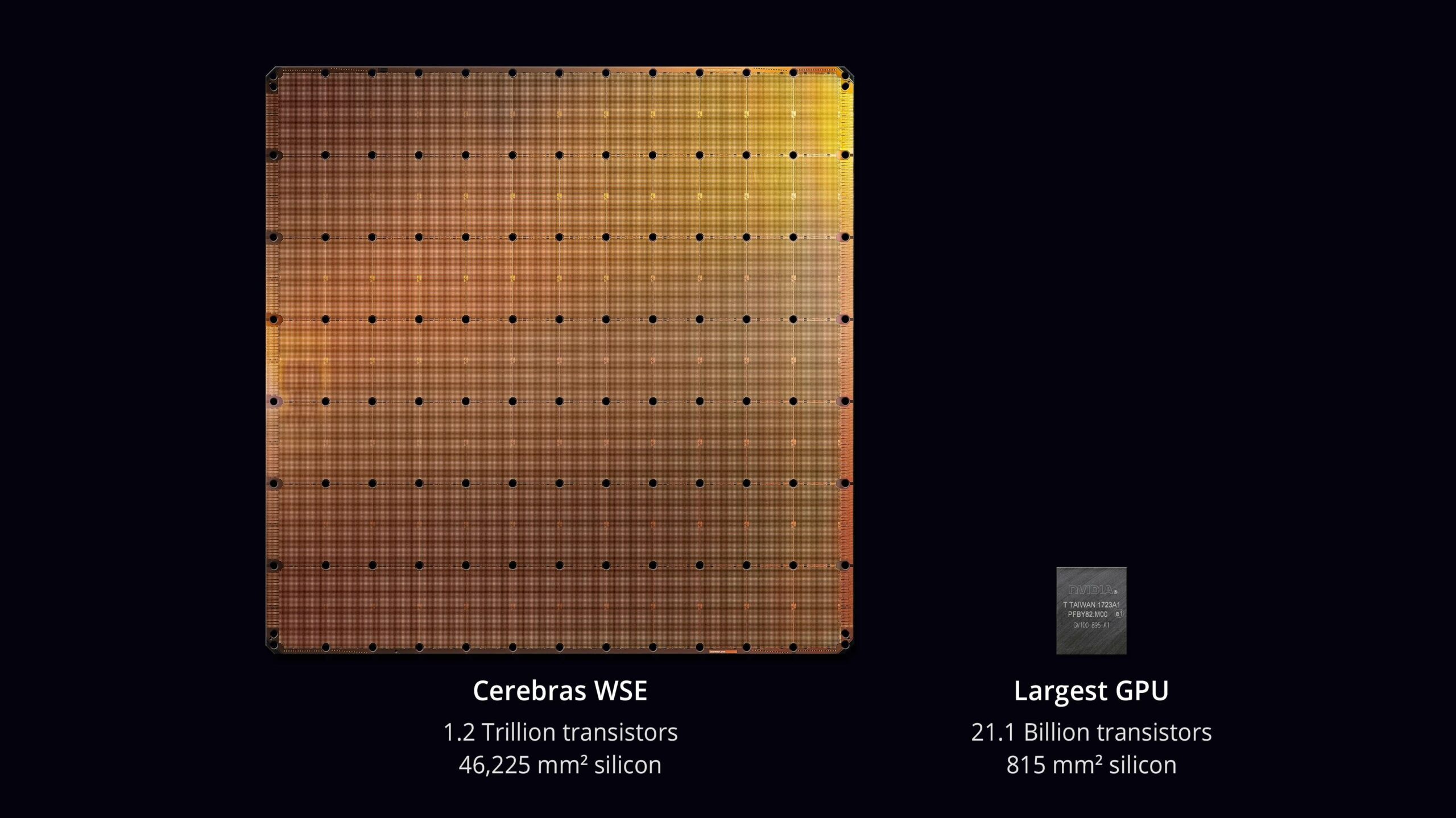
Cerebrasの最大の特徴は、「Wafer Scale Engine」と呼ばれる巨大なチップです。
通常のチップはウエハから切り出された小さなチップですが、Cerebrasはウエハそのものをチップとして活用しています。
これはウエハスケールと呼ばれ、膨大な数のプロセッサコア(90万個)を搭載することを可能にし、従来のチップでは不可能だった処理能力を実現しています。
3. 驚異の処理速度とプログラミングの簡潔さ:NVIDIA GPUとの比較
Cerebrasのチップは、AIの学習プロセスにおいて、NVIDIAの最新GPUであるH100と比較して圧倒的な処理速度を誇ります。
これは、巨大なチップによってチップ間の通信を削減し、処理のボトルネックを解消しているためです。
チップ間通信が必要なNVIDIAのGPUと比べて、Cerebrasのチップは3000倍以上の通信速度を実現していると言われています。
また、AIの推論プロセスにおいても、NVIDIAのGPUよりも最大20倍高速に処理できるという驚異的な性能を実現しており、電力消費と処理時間の削減により、運用コスト全体を低減できる可能性があります。
さらに、Cerebrasは巨大なチップをクラスター化して繋いでも、あたかも一つのチップとしてプログラミングできる環境を整えました。
その結果、巨大なパラメータ数を持つLLMのプログラミングが、従来のGPUを用いた場合と比べて、(コード量で)24倍簡単になっているそうです。
例えば、1.7兆パラメータを持つ巨大言語モデル「GPT-4」の開発には、240人以上の開発者が参加し、そのうち35人は分散トレーニングとスーパーコンピューティングの専門家だったそうです。
Cerebrasのチップを使えば、GPT-4のような巨大なモデルの開発においても、分散トレーニングの専門家35人を削減できる可能性があり、開発リソースの効率化を行える可能性があります。
4. ウエハサイズチップの課題:歩留まりとソフトウェア
ウエハスケールの巨大チップを作る斬新さは凄まじいですが、チップのサイズを大きくすると、歩留まり(正常に動作するチップの割合)が極端に下がることが課題となります。
しかし、Cerebrasは、90万個あるプロセッサ・コアの5%が不良品であっても大丈夫なような設計にすることにより、ウエハ・サイズのチップの運用が可能となるように工夫しているそうです。
それでも、1チップで処理できないほど巨大なモデルが登場した場合、複数のチップに分割して処理し、その部分はソフトウェアで補う必要が出てきます。
そして、もしNVIDIAが同様のチップ間連携ソフトウェアを提供するようになれば、Cerebrasの優位性は消えてしまう可能性も懸念されます。
5. NVIDIAの強み:CUDAによってGPUプログラミングが簡単にできる

NVIDIAの強みは、GPUテクノロジーにおける長年の経験と、CUDAによって築き上げられたGPUプログラミングの書きやすさにあります。
CUDA(Compute Unified Device Architecture)は、NVIDIAが開発したGPUを用いた並列処理プログラミングを容易にするプラットフォームです。
CUDAを使うことで、C++言語などの使い慣れた言語でGPUの性能を最大限に引き出すプログラムを書くことが可能になっています。
CUDAは広く普及しており、多くのソフトウェアがCUDAに対応しているため、NVIDIAのGPUはAIトレーニングや推論だけでなく、ゲームや科学計算など幅広い用途で活用されています。
6. 大規模言語モデル(LLM)でCerebrasの活躍が期待される

Cerebrasのチップは、特に近年注目を集めている大規模言語モデル(LLM)の開発において大きな力を発揮すると期待されています。
LLMは膨大なデータを使って学習するため、Cerebrasのチップが持つ圧倒的な処理能力とメモリ容量はLLMの開発に最適です。従来、LLMの学習には膨大な時間がかかっていましたが、Cerebrasのチップによって学習時間を大幅に短縮できる可能性があります。
補足:大規模言語モデル(LLM)とは?
大規模言語モデル(LLM:Large Language Model)とは、大量のテキストデータを使って学習された、自然言語処理を行うAIモデルです。
LLMは、人間のように自然な文章を生成したり、質問に答えたり、翻訳したりすることができます。近年、ChatGPT o1-previewやGemini、Claudeといった高性能なLLMが登場し、AIによる自然言語処理は大きな進歩を遂げています。
LLMの特徴は、その巨大なパラメータ数と、学習に用いるデータ量の多さにあります。例えば、o1-previewは2000億個のパラメータを持ち、非常に高い計算能力とメモリ容量を持つAIチップが必要となります。
CerebrasのWafer Scale Engineは、まさにLLMの学習に最適なAIチップと言えるでしょう。
7. どちらが向いている?:CerebrasとNVIDIAのターゲット層
Cerebrasが向いているユーザー
- 最先端のAI研究者: 巨大なAIモデルを扱う最先端の研究を行い、処理速度を限界まで追求したい研究者にとって、Cerebrasは強力です。特に、自然言語処理など、大規模なデータセットを扱う分野においては、この処理能力が大きなメリットとなりそうです。
- 大規模なAIモデルを扱う企業: 大規模なAIモデルをビジネスに活用したい企業にとっても、Cerebrasは魅力的です。例えば、巨大な言語モデルを用いた高精度なチャットボットの開発や、大量の画像データを扱う自動運転システムの開発など、Cerebrasの処理能力は競争力を高める上で重要な役割を果たしそうです。
- 複雑なプログラミングから解放されたいAI開発者: GPUを用いたAI開発では、複数のGPUを連携させるための複雑なプログラミングが必要でした。Cerebrasは、巨大な単一チップで処理を行うため、プログラミングが大幅に簡略化されます。これにより、AI開発者はモデルの設計や学習アルゴリズムの開発といった、本質的な部分に集中することができます。
NVIDIAが向いているユーザー
- 幅広い分野の開発者: NVIDIAのGPUは、AIだけでなく、ゲームやシミュレーション、科学計算など、幅広い分野で利用されています。CUDAとそのエコシステムを活用することで、様々なアプリケーションを効率的に開発することができます。
- コストパフォーマンスを重視する開発者: NVIDIAのGPU単体は、Cerebrasのチップと比較して安価であることが予想され、幅広い価格帯の製品がラインナップされています。そのため、予算を抑えたい開発者や、小規模なプロジェクトに最適です。
- 豊富なライブラリやツールを活用したい開発者: NVIDIAは、CUDAをはじめとする豊富なライブラリやツールを提供しています。これらを活用することで、AI開発を効率的に進めることができます。また、多くの開発者がCUDAに精通しているため、情報共有や技術サポートを受けやすいというメリットもあります。
8. まとめ:Cerebrasは巨人NVIDIAを倒せる?
Cerebrasは、ウエハスケールの巨大チップによって、AI学習の処理速度とプログラミングの容易さを飛躍的に向上させる可能性を秘めています。
しかし、AIモデルの巨大化は今後も続く可能性が高いですし、Cerebrasのチップでも処理しきれない可能性も考えられます。
さらに、NVIDIAがチップ間連携をスムーズに行えるソフトウェアを開発すれば、Cerebrasの優位性が失われる可能性もあります。
今後Cerebrasのように学習プロセスを手軽にする企業が増え、互いに競い合うことで、AIの学習や開発が個人でも行える時代が訪れるかもしれません。
そんな未来が実現して、個人がAI学習でも活躍できるようになることを期待したいですね!
参考元:Cerebras AI Day – Opening Keynote – Andrew Feldman – YouTube







コメントする